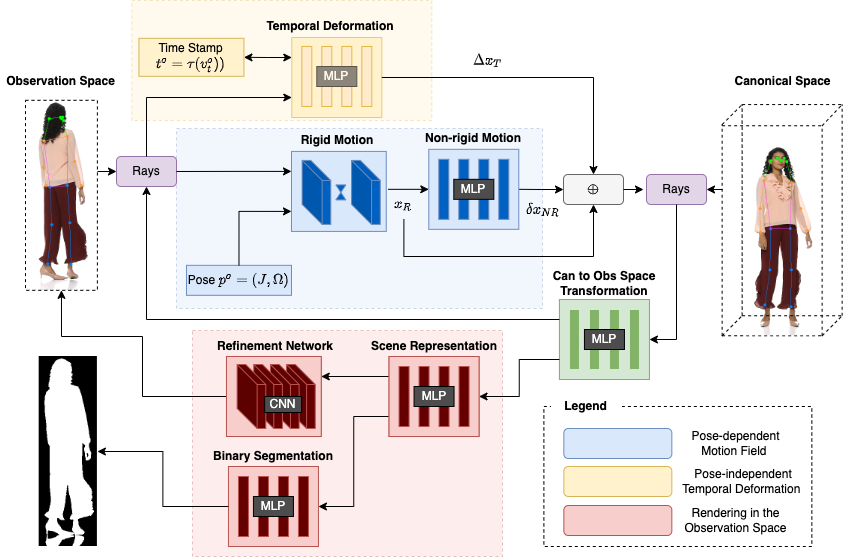
We present FlexNeRF, a method for photorealistic free-
viewpoint rendering of humans in motion from monocular
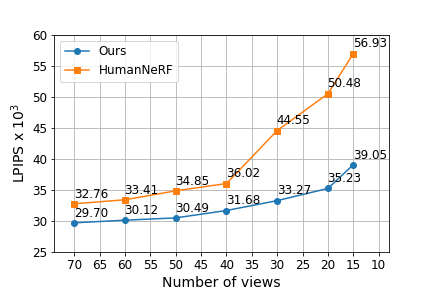
videos. Our approach works well with sparse views, which
is a challenging scenario when the subject is exhibiting
fast/complex motions.
We propose a novel approach which
jointly optimizes a canonical time and pose configuration,
with a pose-dependent motion field and pose-independent
temporal deformations complementing each other. Thanks
to our novel temporal and cyclic consistency constraints
along with additional losses on intermediate representation
such as segmentation, our approach provides high quality
outputs as the observed views become sparser.
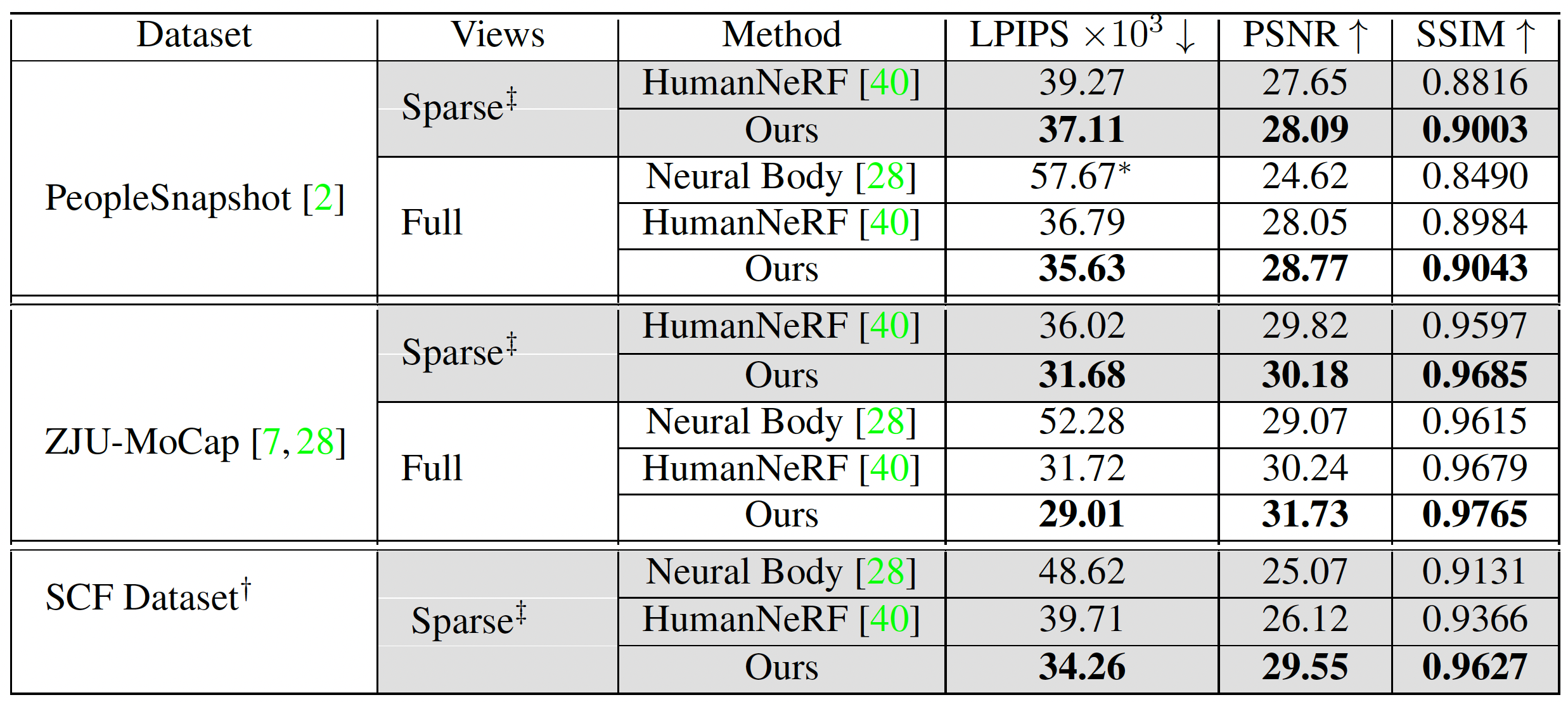
We empirically demonstrate that our method significantly outperforms
the state-of-the-art on public benchmark datasets as well as
a self-captured fashion dataset.